
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Very Deep Convolutional Networks for Large-Scale Image Recognition
- instance segmentation
- object detection
- zed-f9p
- VGGNET
- Deep learning
- Batch Normalization: Accelerating Deep Network Training by ReducingInternal Covariate Shift
- ImageNet Classification with Deep Convolutional Neural Networks
- Mask R-CNN
- 논문리뷰
- c099-f9p
- batch normalization
- 딥러닝
- AI
- machine learning
- vggnet리뷰
- Deep Residual Learning for Image Recognition
- ML
- resnet리뷰
- alexnet리뷰
- overfeat
- rtcm
- Paper Review
- ImageNet Classification with Deep Convolutional Neural Networks 리뷰
- ntrip
- batch norm리뷰
- batch norm
- f9p
- RTK
- one-stage
- Today
- Total
zlzon
[논문리뷰][VGGNet] Very Deep Convolutional Networks for Large-Scale Image Recognition 본문
[논문리뷰][VGGNet] Very Deep Convolutional Networks for Large-Scale Image Recognition
zlzon 2021. 7. 28. 11:38이 글은 VGGNet 이라 불리는 'Very Deep Convolutional Networks for Large-Scale Image Recognition' 논문리뷰 입니다.
또한, 저도 아직 공부하는 학생이라 부족한 부분이 많을수 있다는 점 유의하여 읽어주시면 감사하겠습니다.
피드백은 언제나 환영입니다.
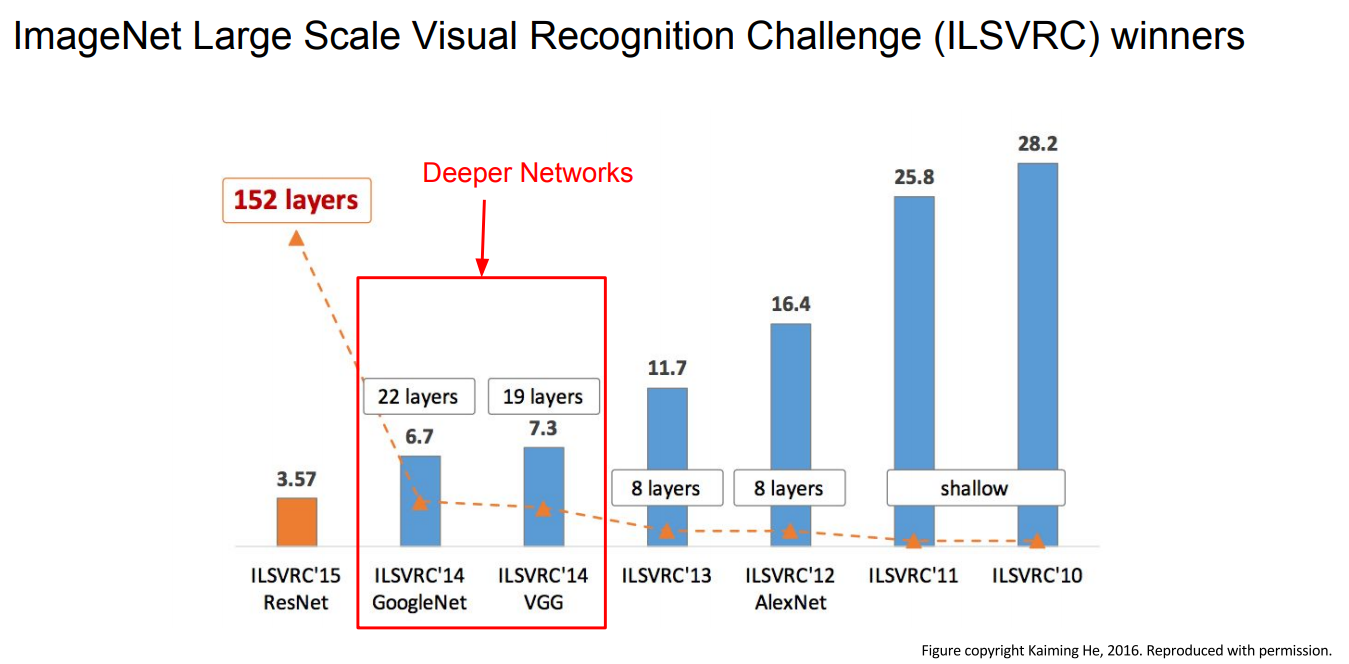
ILSVRC 2014 에서 1, 2등을 차지한 GoogleNet과 VGGNet은 이전모델들에 비해 매우 깊어진다.
(8 layers -> 19, 22 layers)

ILSVRC 2012에서 우승한 AlexNet(8 layers) 과 비교하여 VGG(16 - 19 layer)는 2배가량 깊어졌다.
VGGNet은 항상 이웃픽셀을 포함할 수 있는 가장 작은 필터 3 * 3 필터만 사용한다.
이렇게 작은 필터를 유지해 주고 주기적으로 Pooling을 수행하면서 전체 네트워크를 구성한다.
VGGNet은 아주 심플하면서도 고급진 아키텍쳐이고 ImageNet에서 7.3%의 Top5 Error를 기록했다.
Abstract
VGGNet에서는 CNN네트워크의 depth가 정확도에 미치는 영향에 대해 실험하며, depth를 증가시키면서도
overfitting, gradient vanishing을 어떻게 해결하였는지에 대해 설명한다.
1. Introduction
VGGNet에서는 ConvNet구조의 깊이에 중점을 둔다. 이를 위해 다른 parameter들은 모두 고정시킨채
3 * 3 필터를 활용해 convolutional layers를 추가하여 네트워크의 깊이를 늘린다.
결과적으로 다른 dataset에 대해서도 적용가능한 상당히 더 정확한 ConvNet architectures를 만들어낸다.
2. ConvNet Configurations
깊이증가에 따른 ConvNet의 공정한 성능측정을 위해 모든 ConvNet 계층구성은 동일한 원칙을 사용해 설계한다.
2.1 Architecture
input : trainning set의 각 pixel에 평균 RGB 값을 빼준 전처리를 거친 224 * 224 RGB image
입력된 이미지는 3 * 3 필터를 적용한 ConvNet을 통과하며, 비선형성을 위해 1 * 1 필터도 적용한다.
stride = 1이 적용되고 공간 해상도 유지를 위해 3 * 3 conv layer에 대해 1pixel에 padding을 적용한다.
Max-pooling은 2 * 2pixel 에서 stride = 2 로 수행된다.
Conv layers에 뒤에는 3개의 FC-layer가 뒤따른다. 첫번째와 두번째 FC-layer는 각 4096개의 채널을 가지고 마지막 세번째는 1000개의 채널을 가진다. FC-layer 다음으로는 Soft-max Layer가 뒤따른다. FC-layer의 구성은 모든 네트워크에서 동일한다. 모든 hidden layer에 활성화 함수로 ReLU를 사용하며 AlexNet에 적용된 LRN(Local Response Normalization)는 VGGNet 성능에 영향이 없기 때문에 적용하지 않는다.

2.2 Configurations
Table 1 에서 깊이에만 변화를 준 모델 A - E (11 - 19 layers)가 명시되어있다. Conv layer의 width는 64 로 시작하여
max-pooling을 거칠때 2배씩 증가하여 512 까지 증가한다.
Table 2 에서는 각 모델의 parameter 수가 명시되어있다.

2.3 Discussion
VGGNet은 ILSVRC-2012/2013 우승작 AlexNet/ZFNet과 달리 모델 전체에 매우 작은 3 * 3 필터(stride = 1)를 사용한다.
3 * 3 필터 2개 = 5 * 5 필터 1개
3 * 3 필터 3개 = 7 * 7 필터 1개
와 같은 성능을 보인다. 그렇다며 굳이 3 * 3 필터를 여러개 사용하여 얻는 이점은 무엇일까?
그 이점은 decision function 성능이 더 향상되며, parameter 개수를 줄일수 있다는 것이다.
모델이 C개의 채널을 가진다 가정하면, 3 * 3 필터 3개 사용시 3 * ( 3² C² ) = 27C² 인 반면,
7 * 7 필터 1개 사용시 1 * ( 7² C² ) = 49C² 이다. 즉 3 * 3 필터 3개 사용시 parameter 개수를 81%가량 줄일수 있다.
1 * 1 conv layer (모델C, Table 1)은 decision function의 비선형성을 늘리기 위해 사용한다. 또한, 입력과 출력의
channel을 동일하게하고, ReLU를 거치면서 추가적인 비선형성을 가질수 있다.
3. Classification Framework
이번 section에서는 ConvNet tranning, evaluation의 세부사항을 설명한다.
3.1 Trainning
ConvNet training과정은 input image crop을 제외하고는 AlexNet과 동일하게 진행된다.
즉, trainning은 momentum이 있는 mini-batch gradient descent를 사용한다.
- batch size = 256
- momentum = 0.9
- weight decay = 0.0005
- drop out = 0.5
- epoch = 74
- learning rate = 0.01(10배씩 감소)
VGGNet은 AlexNet과 비교하여 더 많은 parameter, depth를 가짐에도
(a) 작은 필터사이즈, (b) 특정 layer에서 pre-initialisation 덕분에 더 적은 epoch을 가진다.
pre-initialisation
VGGNet은 모델 A를 random initialisation을 적용해 학습시킨후, 더 깊은 모델을 학습시킬때
처음 4개의 Conv layer와 마지막 3개의 FC-layer에 대해 학습된 모델 A의 layer를 활용한다.
VGGNet팀은 논문 제출후 random initialisation procedure of Glorot & Bengio (2010)을 이용하면 pre-training 없이
가중치초기화가 가능하다는 것을 알았다.
data augmentation
( 1 ) 224 * 224 size로 crop된 이미지 랜덤으로 수평 뒤집기
( 2 ) 랜덤으로 RGB값 변경
( 3 ) Training image rescale
S = training scale
1. single-scale training
S = 256 or S = 384 로 고정
2. multi-scale training (scale jittering)
S를 256 - 512 값중 random하게 설정
3.2 Testing
Training 완료된 모델을 테스팅할 때 마지막 3개 FC-layer를 Conv layer로 변환하여 사용한다.
첫 번째 FC-layer는 7 * 7 Conv layer로, 나머지 2개의 FC-layer는 1 * 1 Conv layer로 변환한다.
이런식으로 변환된 신경망을 Fully-Convolutional Networks(FCN) 이라 부른다.
신경망이 Conv layer로만 구성도리 경우 input 이미지 크기 제약이 없어진다. 이에 따라 하나의 입력 이미지를 다양한 스케일로 사용한 결과들을 앙상블하여 이미지 분류 정확도를 개선하는 것도 가능해진다.
4. Classification Experiments
실험에서 validation set을 test set으로 이용한다.
4.1 Single Scale Evaluation
1. 모델 A에서 Local Response Normalisation(LRN)을 적용한 결과 큰 성능향상이 없어
나머지 모델에서는 LRN을 적용하지 않는다.
2. ConvNet depth가 증가할수록 classification error가 감소했다.
3. scale jittering이 더 좋은 성능을 보인다.

4.2 Multi-Scale Evaluation
동일한 모델 학습에서 scale jittering을 적용한 것이 single scale적용한것보다 더 좋은 성능을 보인다.

4.3 Multi-Crop Evaluation
multi-crop과 dense를 함께 사용할 때 가장 좋은 성능을 보인다.

참고 사이트
https://deep-learning-study.tistory.com/398
https://codebaragi23.github.io/machine%20learning/1.-VGGNet-paper-review/



