
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Deep Residual Learning for Image Recognition
- rtcm
- batch norm
- ntrip
- vggnet리뷰
- Very Deep Convolutional Networks for Large-Scale Image Recognition
- machine learning
- ImageNet Classification with Deep Convolutional Neural Networks 리뷰
- Deep learning
- one-stage
- ImageNet Classification with Deep Convolutional Neural Networks
- VGGNET
- 논문리뷰
- instance segmentation
- zed-f9p
- f9p
- ML
- overfeat
- Paper Review
- c099-f9p
- AI
- resnet리뷰
- 딥러닝
- RTK
- object detection
- batch norm리뷰
- Batch Normalization: Accelerating Deep Network Training by ReducingInternal Covariate Shift
- alexnet리뷰
- batch normalization
- Mask R-CNN
- Today
- Total
zlzon
[논문리뷰][R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation 본문
[논문리뷰][R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation
zlzon 2021. 10. 28. 13:23이 글은 'R-CNN', 'Rich feature hierarchies for accurate object detection and semantic segmentation'
논문리뷰 입니다. 아직 공부하는 학생이라 부족한 부분이 많을수 있다는 점 유의하여 읽어주시면 감사하겠습니다.
피드백은 언제나 환영입니다.
Abstract
R-CNN은 PASCAL VOC dataset을 사용하여 best result of VOC2012 기준 30%이상 성능(mAP)이 향상되고 심플하며 확장가능한 알고리즘을 제안한다. 또한 R-CNN 두가지 중요한 아이디어를 결합한다.
1. localize, segmentation을 위해 bottom-up방식의 region proposals에 CNN을 적용한다.
2. labeled training data가 부족하면, domain-specific fine-tuning을 통해 성능을 향상시킬수 있다.
CNN에 region proposals을 결합하여 R-CNN이라고 부른다.
R-CNN system Overview
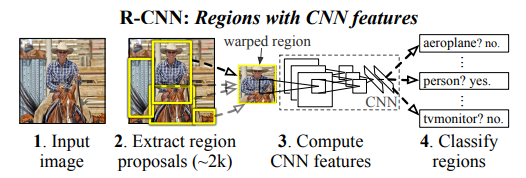
1. Selective search를 이용해 2,000개의 Region proposal를 추출한다.
2. 각 Region proposal에 대하여 warping을 수행하여 동일한 크기(227 * 227)의 입력 이미지로 변경한다.
3. Warped image를 CNN에 넣어서 이미지 feature를 추출한다.
4. 해당 feature를 SVM에 넣어 클래스 분류 결과, regressor에 넣어 bounding box를 예측한다.
1. Region proposal
Selective search

Selective serch 알고리즘을은 색상, 무늬, 명암 등의 다양한 기준으로 픽셀을 grouping하고, 점차 통합시켜 객체가 있을법한 위치를 bounding box형태로 추천한다.
2. CNN
CNN은 Conv layer 5개 + Fc layer 2개의 AlexNet 형태를 사용하며, ILSVRC 2012 데이터 셋으로 미리 학습된 pre-trained CNN 모델을 사용했으며, Object detection을 적용할 dataset으로 fine-tunning 한다.
2000개의 후보영역을 CNN에 입력하여 2000 * 4096 크기의 feature vector를 추출한다.
3. SVM classifier
SVM 모델은 특정 class에 해당하는지 여부만을 판단하는 이진 분류기(binary clasffier)이다.
CNN으로 추출한 2000 * 4096 feature vector를 SVM을 이용하여 분류한다.
클래스의 개수가 N개라면, 배경을 포함한 (N+1)개의 독립적인 SVM모델을 학습시켜야 한다.
문제점
입력 이미지에 대하여 CPU 기반의 Selective Search를 진행해야 하므로 많은 시간이 소요된다.
전체 아키텍터에서 SVM, Regressor 모듈이 CNN이 분리되어 있어 end-to-end 방식으로 학습할 수 없다.
모든 region을 CNN에 넣어야 하기 때문에 2000번의 CNN 연산이 필요하다.
참조사이트
https://herbwood.tistory.com/5
https://deep-learning-study.tistory.com/410
https://www.youtube.com/watch?v=jqNCdjOB15s&t=1016s



